
Wednesday, December 31, 2014
Tuesday, December 23, 2014
Labeling topics from topic models
My friend Charlie Greenbacker showed me LDAvis, which creates interactive apps for visualizing topics from topic models. As often happens, this lead to a back and forth between Charlie and me covering a range of topic modeling issues. I've decided to share and expand on bits of the conversation over a few posts.
A few things pop out pretty quickly.
As I said to Charlie: "Big difference in interpretability, no?"
It's not perfect. I have noticed that similar topics tend to get identical labels. The labeling isn't so good at picking up on subtle differences. Some topics are what I call "methods" rather than "subjects". (This is because most of my topic modeling is on scientific research papers.) The "methods" rarely have a high proportion in any document. The document simply isn't "about" its methods; it's about its subject. When this happens, sometimes I don't get any documents to go with a methods topic. The labeling algorithm just returns "NA". No bueno.
The old way
The traditional method for reporting a topic (let's call it topic X) is to list the top 3 to 5 words in topic X. What do I mean by "top" words? In topic modeling a "topic" is a probability distribution over words. Specifically, "topic X" is really P( words | topic X).
Here is an example from the empirical section of the R-squared paper I'm working on:
"mode" "model" "red" "predict" "tim" "data"
A few things pop out pretty quickly.
- These are all unigrams. The model includes bigrams, but they aren't at the top of the distribution.
- A couple of the words seem to be truncated. Is "mode" supposed to be "model"? Is "tim" supposed to be "time"? It's really hard to tell without any context. (Even if these are truncated, it wouldn't greatly affect the fit of the model. It just makes it look ugly.)
- From the information we have, a good guess is that this topic is about data modeling or prediction or something like that.
The incoherence of these terms on their own requires topic modelers to spend massive amounts of time curating a dictionary for their final model. If you don't, you may end up with a topic that looks like topic 1 in this example. Good luck interpreting that!
(As a complete aside, it looks like topic 1 is the result of using an asymmetric Dirichlet prior for topics over documents. Those that attended my DC NLP talk know that I have ambivalent feelings about this.)
A new approach
I'm going to get a little theoretical on you: Zipf's law tells me that, in theory, the most probable terms in every topic should be stop words. Think about it. When I'm talking about cats, I still use words like "the", "this", "an", etc. waaaaay more than any cat-specific words. (That's why Zipf's law is, well...., a law.)
Even if we remove general stop words before modeling, I probably have a lot of corpus-specific stop words. Pulling those out, while trying to preserve the integrity of my data, is no easy task. (It's also a little like performing surgery with a chainsaw.) That's why so much time is spent on vocabulary curation.
My point is that I don't think P(words | topic X) is the right way to look at this. Zipf's law means that I expect the most probable words in that distribution to contain no contextual meaning. All that dictionary curation is isn't just time consuming, it's perverting our data.
But what happens if we throw a little Bayes' Theorem at this problem? Instead of ordering words by P( words | topic x), let's order them according to P( topic x | words).
"prediction_model" "causal_inference" "force_field" "kinetic_model" "markov" "gaussian"
As I said to Charlie: "Big difference in interpretability, no?"
Full labels
I think that all of our dictionary curation hurts us beyond being a time sink. I think it makes our models fit the data worse. This has two implications: we have less trust in the resulting analysis and our topics are actually more statistically muddled, not less.
We (as in I and some other folks who work with me) have come up with some automated ways to label topics. This method works by grouping documents together by topic and then extracting keywords from the documents. (The difference between my work and the other guys I work with is in the keyword extraction step.)
The method basically works like this:
- For each topic:
- Grab a set of documents with high prevalence of that topic.
- In a document term matrix of bigrams and trigrams, calculate P( words | that set of documents) - P( words in the overall corpus )
- Take the n-gram with the highest score as your label.
- Next topic
My label for "topic X"?
"statistical_method"
It's not perfect. I have noticed that similar topics tend to get identical labels. The labeling isn't so good at picking up on subtle differences. Some topics are what I call "methods" rather than "subjects". (This is because most of my topic modeling is on scientific research papers.) The "methods" rarely have a high proportion in any document. The document simply isn't "about" its methods; it's about its subject. When this happens, sometimes I don't get any documents to go with a methods topic. The labeling algorithm just returns "NA". No bueno.
One last benefit
By not butchering the statistical signals in our documents by heavy-handed dictionary curation, we get some nice properties in the resulting model. One, for example, is that we can cluster topics together cleanly. So, I can create a nice hierarchical dendrogram of all my topics. (I can also use the labeling algorithm to label groups higher up on the tree if I want.)
You can check out one of the dendrograms I'm using for the R-squared paper by clicking here. The boxes are clusters of topics based on linguistic similarity and document occurrence. (It's easier to see if you zoom in.) It's a model of 100 topics on 10,000 randomly-sampled NIH grant abstracts. (You can get your own here.)
Wednesday, December 17, 2014
Notes on the culture of economics
I'm finally getting around to reading Piketty's Capital in the 21st Century. That and a project at work has put economics back to the front of my brain. I found the below posts interesting.
Paul Krugman says in "Notes on the Floating Crap Game (Economics Inside Baseball)"
Not all Krugman says is rosy for economists. Nevertheless, this is consistent with my experience when I was in economics. Econ has a hierarchical structure, but it's not based on patronage or solely "length of service." For example, when I was at the Fed, the internal structure was quite hierarchical in terms of both titles and managerial responsibility. (It kind of reminded me of the military.) However, it also had a paradoxically "flat" culture. Ideas were swapped and debated constantly. Though I was a lowly research assistant, my forecasts were respected and my input listened to. I was no exception; this was just how we operated.
Simply statistics brought another post to my attention. From Kevin Drum at Mother Jones: Economists are Almost Inhumanly Impartial.
(I'll leave it to you to check out the regression line in question.)
Simply statistics's Jeff Leek has a different take.
I don't know what Leek is getting at exactly; maybe we agree. What I see is a nearly flat line through a cloud of points. My take isn't that economists are unbiased. Rather, their bias is generally uncorrelated with their ideology. That's still a good thing, right? (Either way, I am not one for the philosophy of p < 0.05 means it's true and p > 0.05 means it's false.)
Here's what I've told other people: microeconomics is about as close to a science as you're going to get. It's a lot like studying predator prey systems in the wild. There's definitely stochastic variation, but the trends are pretty clear; not much to argue about. Macroeconomics, on the other hand is a lot trickier. It's not that macroeconomists are any less objective than microeconomists. Rather, measurement and causality are much trickier. In the resulting vacuum, there's room for different assumptions and philosophies. This is what macroeconomists debate about.
Nevertheless, my experience backs up a comment to Drum's article:
Translation: the differences in philosophies between macroeconomists isn't as big as you'd think. And they're tiny compared to our political differences.
Paul Krugman says in "Notes on the Floating Crap Game (Economics Inside Baseball)"
So, academic economics is indeed very hierarchical; but I think it’s important to understand that it’s not a bureaucratic hierarchy, nor can status be conferred by crude patronage. The profession runs on reputation — basically the shared perception that you’re a smart guy. But how do you get reputation? [...] [R]eputation comes out of clever papers and snappy seminar presentations.
[...] Because everything runs on reputation, a lot of what you might imagine academic politics is like — what it may be like in other fields — doesn’t happen in econ. When young I would have relatives asking whether I was “in” with the department head or the senior faculty in my department, whether I was cultivating relationships, whatever; I thought it was funny, because all that mattered was your reputation, which was national if not global.
Not all Krugman says is rosy for economists. Nevertheless, this is consistent with my experience when I was in economics. Econ has a hierarchical structure, but it's not based on patronage or solely "length of service." For example, when I was at the Fed, the internal structure was quite hierarchical in terms of both titles and managerial responsibility. (It kind of reminded me of the military.) However, it also had a paradoxically "flat" culture. Ideas were swapped and debated constantly. Though I was a lowly research assistant, my forecasts were respected and my input listened to. I was no exception; this was just how we operated.
Simply statistics brought another post to my attention. From Kevin Drum at Mother Jones: Economists are Almost Inhumanly Impartial.
Over at 538, a team of researchers takes on the question of whether economists are biased. Given that economists are human beings, it would be pretty shocking if the answer turned out to be no, and sure enough, it's not. In fact, say the researchers, liberal economists tend to produce liberal results and conservative economists tend to produce conservative results. This is unsurprising, but oddly enough, I'm also not sure it's the real takeaway here. [...]
What I see is a nearly flat regression line with a ton of variance. [...] If these results are actually true, then congratulations economists! You guys are pretty damn evenhanded. The most committed Austrians and the most extreme socialists are apparently producing numerical results that are only slightly different. If there's another field this side of nuclear physics that does better, I'd be surprised.
(I'll leave it to you to check out the regression line in question.)
Simply statistics's Jeff Leek has a different take.
I'm not sure the regression line says what they think it does, particularly if you pay attention to the variance around the line.
I don't know what Leek is getting at exactly; maybe we agree. What I see is a nearly flat line through a cloud of points. My take isn't that economists are unbiased. Rather, their bias is generally uncorrelated with their ideology. That's still a good thing, right? (Either way, I am not one for the philosophy of p < 0.05 means it's true and p > 0.05 means it's false.)
Here's what I've told other people: microeconomics is about as close to a science as you're going to get. It's a lot like studying predator prey systems in the wild. There's definitely stochastic variation, but the trends are pretty clear; not much to argue about. Macroeconomics, on the other hand is a lot trickier. It's not that macroeconomists are any less objective than microeconomists. Rather, measurement and causality are much trickier. In the resulting vacuum, there's room for different assumptions and philosophies. This is what macroeconomists debate about.
Nevertheless, my experience backs up a comment to Drum's article:
Economists generally avoid and form consensus in regard to fringe theories.
Translation: the differences in philosophies between macroeconomists isn't as big as you'd think. And they're tiny compared to our political differences.
Tuesday, December 16, 2014
Empowering People with Machine Learning
From an article in the Wall Street Journal:
First, there's Tyler Cowen's analogy of freestyle chess. He uses this analogy liberally in Average is Over. And the division of labor between human and computer in freestyle chess mirrors the above quote.
Second, I was taught the dichotomy of these two philosophies in the Marine Corps. I enlisted just before 9/11; ten + years of war may have changed the budgetary environment. But at the time, Marine infantry units did not have much of a budget. As a result, we trained ourselves (and our minds) first, and supplemented with what technology we could afford. On occasional training with some other (unnamed) branches of the military, we observed that these other units were awash in technology, helpless without it, and not any better than us with it. (Think fancy GPS versus old GPS + map & compass.)
I believe that the latter thought is an example of another quote from the WSJ article:
Something to keep in mind as you're implementing your decision support systems.
Two thoughts come to mind:When system designers begin a project, they first consider the capabilities of computers, with an eye toward delegating as much of the work as possible to the software. The human operator is assigned whatever is left over, which usually consists of relatively passive chores such as entering data, following templates and monitoring displays.This philosophy traps people in a vicious cycle of de-skilling. By isolating them from hard work, it dulls their skills and increases the odds that they will make mistakes. When those mistakes happen, designers respond by seeking to further restrict people’s responsibilities—spurring a new round of de-skilling.Because the prevailing technique “emphasizes the needs of technology over those of humans,” it forces people “into a supporting role, one for which we are most unsuited,” writes the cognitive scientist and design researcher Donald Norman of the University of California, San Diego.There is an alternative.In “human-centered automation,” the talents of people take precedence. Systems are designed to keep the human operator in what engineers call “the decision loop”—the continuing process of action, feedback and judgment-making. That keeps workers attentive and engaged and promotes the kind of challenging practice that strengthens skills.In this model, software plays an essential but secondary role. It takes over routine functions that a human operator has already mastered, issues alerts when unexpected situations arise, provides fresh information that expands the operator’s perspective and counters the biases that often distort human thinking. The technology becomes the expert’s partner, not the expert’s replacement.Pushing automation in a more humane direction doesn't require any technical breakthroughs. It requires a shift in priorities and a renewed focus on human strengths and weaknesses
First, there's Tyler Cowen's analogy of freestyle chess. He uses this analogy liberally in Average is Over. And the division of labor between human and computer in freestyle chess mirrors the above quote.
Second, I was taught the dichotomy of these two philosophies in the Marine Corps. I enlisted just before 9/11; ten + years of war may have changed the budgetary environment. But at the time, Marine infantry units did not have much of a budget. As a result, we trained ourselves (and our minds) first, and supplemented with what technology we could afford. On occasional training with some other (unnamed) branches of the military, we observed that these other units were awash in technology, helpless without it, and not any better than us with it. (Think fancy GPS versus old GPS + map & compass.)
I believe that the latter thought is an example of another quote from the WSJ article:
If we let our own skills fade by relying too much on automation, we are going to render ourselves less capable, less resilient and more subservient to our machines.
Something to keep in mind as you're implementing your decision support systems.
Monday, December 15, 2014
Ukrain?
So, I've noticed a trend over the last few month's in the blog's traffic. The vast majority of hits seem to be coming from domains ending in ".ru".

Of course, these are bots. (I am heartened to see that when you aggregate URLs to sites, twitter, meetup, and datasciencecentral are still close to the top.)
When looking at the geography of the traffic sources, I'm seeing a whole lot of... Ukrain?

Who knew stats were so popular in Ukrain? (Kidding.)
But seriously, this only started a few months ago. I'm wondering if the conflict in Ukraine has anything to do with this. It's conceivable that computers and servers are getting hijacked over there as part of the war. Anyone have any thoughts?
Of course, these are bots. (I am heartened to see that when you aggregate URLs to sites, twitter, meetup, and datasciencecentral are still close to the top.)
When looking at the geography of the traffic sources, I'm seeing a whole lot of... Ukrain?
Who knew stats were so popular in Ukrain? (Kidding.)
But seriously, this only started a few months ago. I'm wondering if the conflict in Ukraine has anything to do with this. It's conceivable that computers and servers are getting hijacked over there as part of the war. Anyone have any thoughts?
Thursday, December 11, 2014
Saved by plagiarism!
I am writing a paper on goodness-of-fit for topic models. (Specifically, I've derived an R-squared metric for use with topic models.) I came across this definition for goodness-of-fit in our friend, Wikipedia.
I love it! It's concise and to the point. But do I really want to cite Wikipedia in an article for peer review?
A Google search for the verbatim quote above reveals that this definition appears in countless books, papers, and websites without attribution. Did these authors plagiarize Wikipedia? Did Wikipedia plagiarize these authors? Who knows.
My solution, put the definition in quotes and attach a footnote. "This quote appears verbatim on Wikipedia and countless books, papers, and websites."
Done.
The goodness of fit of a statistical model describes how well it fits a set of observations. Measures of goodness of fit typically summarize the discrepancy between observed values and the values expected under the model in question.
I love it! It's concise and to the point. But do I really want to cite Wikipedia in an article for peer review?
A Google search for the verbatim quote above reveals that this definition appears in countless books, papers, and websites without attribution. Did these authors plagiarize Wikipedia? Did Wikipedia plagiarize these authors? Who knows.
My solution, put the definition in quotes and attach a footnote. "This quote appears verbatim on Wikipedia and countless books, papers, and websites."
Done.
Tuesday, December 9, 2014
Simulating Realistic Data for Topic Modeling
Brian and I have finally submitted our paper to IEEE Transactions on Pattern Analysis and Machine Intelligence. This is the culmination of a year of hard work. (There's more work yet to be done; I doubt we'll make it through peer-review without having to revise.)
I presented our preliminary results at JSM in August, as described in this earlier post.
Here is the abstract.
The rest of the paper can be read here.
I presented our preliminary results at JSM in August, as described in this earlier post.
Here is the abstract.
Latent Dirichlet Allocation (LDA) is a popular Bayesian methodology for topic modeling. However, the priors in LDA analysis are not reflective of natural language. In this paper we introduce a Monte Carlo method for generating documents that accurately reflect word frequencies in language by taking advantage of Zipf’s Law. In developing this method we see a result for incorporating the structure of natural language into the prior of the topic model. Technical issues with correctly assigning power law priors drove us to use ensemble estimation methods. The ensemble estimation technique has the additional benefit of improving the quality of topics and providing an approximation of the true number of topics.
The rest of the paper can be read here.
Monday, December 8, 2014
Look up
I've added a couple pages to the blog here. The about me page has a quick bio. The publications and presentations page is where I'll be putting up my bragging rights research portfolio.
Wednesday, November 26, 2014
Economics and Data Mining

He's mining for data.
I stumbled across this video.
Cosma Shalizi, a stats professor at Carnegie Mellon, argues that economists should stop "fitting large complex models to a small set of highly correlated time series data. Once you add enough variables, parameters, bells and whistles, your model can fit past data very well, and yet fail miserably in the future."
I think there's a bit of a conflation of problems here. Not all economic data sets are small. An economist friend of mine pointed out that he's been working with datasets that have millions of observations. I am told this is common in microeconomics.
Nevertheless, my experience is that "acceptable" econometric methods are overly-conservative. As stated in the video, an economist saying someone is "data mining" is tantamount to an accusation of academic dishonesty. I was indoctrinated early in the ways of David Hendry's general to specific modeling, which is basically data mining (but doing it intelligently). This, I think, made machine learning an intuitive move for me, and I've always thought that economics research would benefit greatly from machine learning methods.
There are some important caveats to all this. First, I don't see anyone beating out economics the same way computer science is sticking it to statistics. For "big data analytics" to live up to its hype, data scientists have to think a lot like economists, not the other way around. A big part of an economics education is economic thinking; this goes above and beyond statistical methods. Second, (and more importantly) you should take anything I say here with a grain of salt. Though I have a background in (and profound love for) economics, I never held a graduate degree in econ and I've been out of the field (and professional network) for several years. My knowledge may be dated.
Even so, I'm happy to hear voices like Dr. Shalizi's. It adds to Hal Varian's paper on "big data" tricks for econometrics. Maybe instead of worrying about the AI singularity, we should be worrying about economists using machine learning and then taking all of our jobs. ;-)
Wednesday, November 19, 2014
What do you do when you see a bad study?
Debate: how should we respond in the face of a study using bad statistics? - This post actually has a bit of history to it, citing Andrew Gelman and Jeff Leeks. I'd recommend clicking through and taking in its totality.
Friday, November 14, 2014
LDA and Topic Models Reading List
Good crowd tonight to hear @thos_jones talk about topic modeling #NLProc #datadc cc: @DataCommunityDC @YourGirlK pic.twitter.com/dthE7z1lRB
— DC NLP Meetup (@DCNLP) November 13, 2014
A big thank you to everyone that came to see me talk about topic models at DC-NLP on Wednesday. I am grateful for the feedback that I received. I'd also like to give a big shout out to my co-author, Brian St. Thomas. Not only has his hard work made our research shine, he is the one who came up with the "ball and urns" graphic to explain topic models. Many people came up to me afterwords saying how intuitive that was; I wish I could take the credit, but it was all Brian.
While I wait on approval from work to release my slides, I thought I'd put together an LDA-related reading list of many of my sources. I've done a bit of that before here. Some of those papers are also below, as well as others.
LDA Basics
- The clearest statement of LDA I've seen is on Wikipedia.
- Here is David Blei et. al's original paper.
- This paper introduces Gibbs sampling for LDA.
On Priors and Zipf's Law
- Rethinking LDA: Why Priors Matter (This is a good paper, though I am skeptical of the conclusion.)
- Comparison of topic models, their estimation algorithms, and priors. (Very underrated, MUST READ.)
- Incorporating Zipf's law in language models
- A note on estimating LDA with asymmetric priors
Evaluating LDA/Issues With LDA
- LDA is an inconsistent estimator
- Reading Tea Leaves: How humans interpret topic models (Also, MUST READ.)
- A coherence (cohesion?) metric for topic models. (Note: This metric has the issue of "liking" topics full of statistically-independent words. It is still useful though.)
Other Topic Models
- Spherical topic models. (
My co-author assures me that these are consistent estimators; we've not yet implemented them though. Know anyone that has?) (Update 2:48: I was wrong, this model is *not* consistent but it could be. See Brian's note, below.) - Dynamic topic models
- Ensembles of topic models (not our stuff, but from Jordan Boyd-Graber who is super smart and a friend of DC-NLP)
Other Stuff
- KERA keyword extraction used to label topics in one of my examples. (The paper applying it to LDA is forthcoming, however.)
- Rethinking Language: How probabilities shape the words we use (MUST READ, though not about topic modeling specifically.)
- David Blei's topic modeling website
From Brian on spherical topic models: "A small note on spherical topic models - the basic spherical topic model that is out there (SAM) is *not* a consistent estimator, but we have a framework to make a consistent estimator from my work on estimating mixtures of linear subspaces by tweaking the prior."
Statistics, Computer Science, and How to Move Forward
I'm still here! Took a break from blogging/Twitter/etc. over the last couple months. My brain needed a break and I picked up a real hobby. But this blog isn't dead yet!
This month's issue of Amstat News features an editorial by Norman Matloff titled "Statistics Losing Ground to Computer Science." Provocative title, no?
I was expecting yet another article whose argument could be summed up as "get off of my lawn, you punk computer scientists!" When I read/hear these kinds of arguments from statisticians, I usually roll my eyes and move on with my life. But this time... I agreed.
Dr. Matloff's article is quite critical of CS research involving statistics. And maybe I'm getting crotchety, but I've run into many of these issues myself in my topic modeling research. An exemplar quote is below.
The fact of the matter is, CS and statistics come from very different places culturally. This doesn't always lend itself to clear communication and cross-disciplinary respect. Dr. Matloff touches on this mismatch. At one end...
And at the other...
I 100% agree with the above. CS didn't start "overshadowing statistics researchers in their own field" simply because computer scientists "move fast and break things." In addition, our (statisticians') conservatism stifled creativity and ambitions to solve grand problems, like facial recognition (or text analyses).
Dr. Matloff recommends several changes for statistics to make. I particularly like the suggestion that more CS and statistics professors have joint appointments. A criticism that I regularly hear from my CS colleagues is that many statisticians are mediocre programmers, and that they lack pragmatism on the tradeoff between mathematical rigor and a useful application. We've covered CS's sometimes cavalier attitude towards modeling above. Perhaps more joint appointments will not only influence faculty, but also educate students early on the needs and advantages of both approaches.
This month's issue of Amstat News features an editorial by Norman Matloff titled "Statistics Losing Ground to Computer Science." Provocative title, no?
I was expecting yet another article whose argument could be summed up as "get off of my lawn, you punk computer scientists!" When I read/hear these kinds of arguments from statisticians, I usually roll my eyes and move on with my life. But this time... I agreed.
Dr. Matloff's article is quite critical of CS research involving statistics. And maybe I'm getting crotchety, but I've run into many of these issues myself in my topic modeling research. An exemplar quote is below.
Due in part to the pressure for rapid publication and the lack of long-term commitment to research topics, most CS researchers in statistical issues have little knowledge of the statistics literature, and they seldom cite it. There is much “reinventing the wheel,” and many missed opportunities.
The fact of the matter is, CS and statistics come from very different places culturally. This doesn't always lend itself to clear communication and cross-disciplinary respect. Dr. Matloff touches on this mismatch. At one end...
CS people tend to have grand—and sometimes starry-eyed—ambitions. On the one hand, this is a huge plus, leading to highly impressive feats such as recognizing faces in a large crowd. But this mentality leads to an oversimplified view, with everything being viewed as a paradigm shift.
And at the other...
Statistics researchers should be much more aggressive in working on complex, large-scale, “messy” problems, such as the face recognition example cited earlier.
I 100% agree with the above. CS didn't start "overshadowing statistics researchers in their own field" simply because computer scientists "move fast and break things." In addition, our (statisticians') conservatism stifled creativity and ambitions to solve grand problems, like facial recognition (or text analyses).
Dr. Matloff recommends several changes for statistics to make. I particularly like the suggestion that more CS and statistics professors have joint appointments. A criticism that I regularly hear from my CS colleagues is that many statisticians are mediocre programmers, and that they lack pragmatism on the tradeoff between mathematical rigor and a useful application. We've covered CS's sometimes cavalier attitude towards modeling above. Perhaps more joint appointments will not only influence faculty, but also educate students early on the needs and advantages of both approaches.
Tuesday, September 2, 2014
Recommendation systems on my mind

I've got recommendation systems on the brain today. Here are links to the sources I've been finding most helpful.
- If you insist, here's chapter 9 from Mining Massive Datasets
- Actually, Jeff Ullman has some pretty awesome stuff up in general.
- A good lit review on collaborative filtering algorithms
Friday, August 22, 2014
Friday links: August 22, 2014

Source: xkcd, retreived from Revolution Analytics
Scince establishes a statistical review panel (hopefully to avoid this)
JHU/Coursera Data Science Track gets an NLP-based capstone
Before working at a startup, get a job at a big company
Related: How to make employees happy (Number one is my favorite)
Being a data scientist means lots of data curation
How to determine the order of authors for your next paper
Monday, August 18, 2014
From JSM 2014: Steven Stigler's Seven Pillars of Statistics
The full list plus explanations can be found here.
In response to those that fall in the "more data means we don't have to worry about anything camp":
I have noticed lately that when I tell people they might be better off with a well-collected sample, rather than trying to get "all the data" they look at me like I've lost my mind.
Then there's this:
In response to those that fall in the "more data means we don't have to worry about anything camp":
The law of diminishing information: If 10 pieces of data are good, are 20 pieces twice as good? No, the value of additional information diminishes like the square root of the number of observations, which is why Stigler nicknamed this pillar the "root n rule." The square root appears in formulas such as the standard error of the mean, which describes the probability that the mean of a sample will be close to the mean of a population.
I have noticed lately that when I tell people they might be better off with a well-collected sample, rather than trying to get "all the data" they look at me like I've lost my mind.
Then there's this:
Design: R. A. Fisher, in an address to the Indian Statistical Congress (1938) said "To consult the statistician after an experiment is finished is often merely to ask him to conduct a post mortem examination. He can perhaps say what the experiment died of."Of course, maybe actually I have lost my mind; I chose to be a statistician. :)
Friday, August 15, 2014
Tuesday, August 12, 2014
Pew canvasses experts on "AI, Robotics, and the Future of Jobs"

From the report:
Key themes: reasons to be hopeful
- Advances in technology may displace certain types of work, but historically they have been a net creator of jobs.
- We will adapt to these changes by inventing entirely new types of work, and by taking advantage of uniquely human capabilities.
- Technology will free us from day-to-day drudgery, and allow us to define our relationship with “work” in a more positive and socially beneficial way.
- Ultimately, we as a society control our own destiny through the choices we make.
Key themes: reasons to be concerned
- Impacts from automation have thus far impacted mostly blue-collar employment; the coming wave of innovation threatens to upend white-collar work as well.
- Certain highly-skilled workers will succeed wildly in this new environment—but far more may be displaced into lower paying service industry jobs at best, or permanent unemployment at worst.
- Our educational system is not adequately preparing us for work of the future, and our political and economic institutions are poorly equipped to handle these hard choices.
Read the full report here.
Monday, August 11, 2014

Thursday, July 24, 2014
An update on "A Comparison of Programming Languages in Economics"
A couple weeks ago, I beat up an NBER working paper, A Comparison of Programming Languages in Economics. My response was a bit harsh though not entirely unfounded. However, there were some points on which I was clearly wrong, as I'll explain below.
The post also lead to a fruitful back and forth between the authors, particularly Jesus Fernandez-Villaverde, and me. (I also gather that others responded to the earlier version as well.) The result is an updated and much-improved version of their working paper. It incorporates the usage of Rcpp and includes a note on vectorizing the problem. In the end, I think the new version does R justice in its advantages and limitations.
In my earlier post, I made three basic points:

The post also lead to a fruitful back and forth between the authors, particularly Jesus Fernandez-Villaverde, and me. (I also gather that others responded to the earlier version as well.) The result is an updated and much-improved version of their working paper. It incorporates the usage of Rcpp and includes a note on vectorizing the problem. In the end, I think the new version does R justice in its advantages and limitations.
In my earlier post, I made three basic points:
- One must consider a programming language's preferred paradigm (functional programming, vector operations, etc.) in comparing languages. This affects the speed of different problems and the human burden of coding.
- R's paradigm is geared towards vector operations. If a vectorized approach exists, R will almost uniformly perform it much faster than in a loop. (While for loops aren't always bad in R. Nesting them together is.)
- R fails hard on problems that don't vectorize (or don't vectorize well). This makes functional knowledge of C/C++ a "must" for R coders, at least intermediate to advanced ones. Rcpp makes integrating C++ code in R incredibly easy.
In my email exchanges with the authors, I also raised an additional point.
- Dynamically re-assigning values to objects in the middle of loops greatly impacts performance.
An example of the above and its assumed-preferred alternative is below.
for( j in 1:100){
x <- j + 1
}
The assumed better alternative would be
x <- rep(0, 100)
for( j in 1:100){
x[ j ] <- j + 1
}
The stuff I got wrong
Last thing's first: Dynamic reassignment of a scalar is considerably faster than initializing a vector beforehand. Dynamic reassignment of a vector is slower than initializing the vector beforehand. This is my mistake.
Second, my knee-jerk reaction to seeing triple-nested for loops inside of a while loop was understandable for the general case but off the mark in this specific case. As the new copy of the working paper indicates, vectorization does not work well for this problem. This does, however, highlight one of R's limitations. If your problem does not vectorize and cannot be run in parallel, you're kind of screwed if you don't know another language.
The stuff that was worth listening to
For better or worse, C/C++ are a big part of optimizing R. When we say "R is optimized for vector operations," we really mean "R's vector operations, like matrix algebra, are actually written in C." As a result, knowing C/C++ (or maybe even FORTRAN) is a part of R. Fortunately Rcpp makes this fairly painless and dispatches with much of the confusing programming overhead involved with C++ coding.
The problem that Drs Aruoba and Fernandez-Villaverde used for their speed test is a prime candidate for some Rcpp. This is also an example of what I mean by adopting a language's assumed paradigm. The "correct" R solution to this problem is to code it in C++, not R. Use R to reshape the data on the front end, call the C++ code that does the main analysis, and then use R to reshape the result, make your graphics etc.
One last thing
I am still dubious of the utility of speed tests for most research applications. I've certainly run into times when speed matters, but those tend to be the exception rather than the rule. Though the authors made two points in our emails: speed is easy to measure, while other criteria are not; and many modern macroeconomic problems can take weeks to estimate in C++ or similar, making speed a more mainstream concern.
R is also poorly-represented in its comparison of coding speed, and I'm not talking about using Rcpp. In 90% or more of the cases I've seen where R is performing abysmally, it is because of user error. Specifically, the R code is written like C/C++ code, lots of loops and "if" statements, rather than matrix operations and the use of logical vectors. Writing R code like it's... well... meant for R, is generally the best fix.
Forgive me for relying on anecdote, but I've written R code that works as well or better than some Python code. The issue was with how the code was written, not the property of the language. (I am sure the "best" Python code is faster than the "best" R code, but how often is it the case that we're all writing our "best" code?)
With those caveats: Drs Aruoba and Fernandez-Villaverde's new paper is not one I'd take much issue with, at least with its treatment of R. They give treatment to 3 clear and easy solutions to approaching their problem in R: raw R code, compiled R code, and Rcpp; the result is plain to see. Unlike other approaches I've seen, this paper shows you how fast R really is compared to other languages.
Tuesday, July 15, 2014
Recap: NLP toolkit (focus on R)
A quick synopsis of last week's DC2 presentation on NLP in Python and R: The talk was hosted jointly by Statistical Programming DC, Data Wranglers DC, and Natural Language Processing DC.

Charlie Greenbacker presented on NLP in Python. His code and write up is here.
I presented on NLP in R. My code, slides, and example data are here.
If I had to sum up the big take aways from the R bit...
- Use R because you are focused on quantitative research. R has big advantages in the quant realm, but sharp edges in terms of memory usage and (sometimes) speed. If you are working on a general programming application, use a GPL.
- The key data structure is a document term matrix (DTM).
- Use sparse representations of the DTM so you don't run out of memory.
- Use linear algebra wherever possible. R likes linear algebra; it's linear algebra functions (e.g. "%*%") are coded in C and are fast.
- Parallelize wherever possible. You have many choices for easy parallelization in R. I like snowfall.
- Remember, the DTM is a matrix. Once you have that, it's (mostly) just math from here on out. Have fun!

Friday, July 11, 2014
On the lack of Friday links lately
The summer of 2014 is turning into one of the busiest I've yet had. Between work, courses, presentations, and friends getting married, I've been spending less time reading which means fewer links for the blog. :(
On deck over the next couple weeks though:
On deck over the next couple weeks though:
- I'll post slides from Wednesday night's talk along with a little write-up.
- Related to the talk, actually, I'll give my overdue review of the high-performance computing in R workshop.
- I'll hopefully get a preview of what's going to be presented at JSM up here for all of you that love topic models as much as I do. (Also, I now have a co-author. Ish just got real.)
Stay tuned!
Example 47,385 of poor coding being blamed on R
I am beginning to think of speed tests of programming languages as being just about useless. An NBER working paper, A Comparison of Programming Languages in Economics, (un-gated version here) is only reenforcing the point.
In my mind, this is a poor choice and is itself more biased. Part of choosing a programming language is choosing your programming paradigm. A more fair comparison would be to adopt the dominant paradigm of each language and compare speeds that way. This choice essentially pits poorly-written R code against well-written C++ code. How is this helpful?
The authors also make the following claims:
First, I have found that the larger the vector, the more vectorization is an important concept in R.(Edit 7/14/2014 - In fairness, I am not sure that the authors' procedure would vectorize well anyway.) Second, I do not buy the implication that coding in C++ on its own is somehow much less cumbersome that calling a single Rcpp function to import that C++ code as a function to be called from R.
Their R code, by the way, had an "if" statement in the middle of 3 nested "for" loops which were themselves nested in a "while" loop. Ummmm.... yeah.
Oh, yes. I do believe that R code written that way was "500 to 700 times slower than C++." Imagine that...
The authors run a common macroeconometric model in a handful of languages and compare speeds. There is a twist, however.
To make the comparison as unbiased as possible, we coded the same algorithm in each language (which could reflect more about our knowledge of each language than its objective virtues.)
In my mind, this is a poor choice and is itself more biased. Part of choosing a programming language is choosing your programming paradigm. A more fair comparison would be to adopt the dominant paradigm of each language and compare speeds that way. This choice essentially pits poorly-written R code against well-written C++ code. How is this helpful?
The authors also make the following claims:
Issues such as avoiding loops through vectorization, which could help Matlab or R, are less important in our case. With 17,820 entries in a vector, vectorization rarely helps much in comparison with standard loops.
We did not explore the possibility of mixing language programming such as Rcpp in R. While such alternatives are often useful (although cumbersome to implement), a detailed analysis falls beyond the scope of this paper.
First, I have found that the larger the vector, the more vectorization is an important concept in R.(Edit 7/14/2014 - In fairness, I am not sure that the authors' procedure would vectorize well anyway.) Second, I do not buy the implication that coding in C++ on its own is somehow much less cumbersome that calling a single Rcpp function to import that C++ code as a function to be called from R.
Their R code, by the way, had an "if" statement in the middle of 3 nested "for" loops which were themselves nested in a "while" loop. Ummmm.... yeah.
Oh, yes. I do believe that R code written that way was "500 to 700 times slower than C++." Imagine that...
Wednesday, July 9, 2014
Today! NLP Toolkit: Python and R
Data Community DC (DC2) is holding a joint meetup with Statistical Programming DC, Data Wranglers DC, and Natural Language Processing DC. The topic: Natural Language Processing (NLP) tools. The first presentation is on Python; the second (presented by yours truly) is on R.
There is more on DC2's blog.
I am both excited and terrified. I'm excited because I love using R for NLP. I'm terrified because we've got 350 RSVPs.
There is more on DC2's blog.
I am both excited and terrified. I'm excited because I love using R for NLP. I'm terrified because we've got 350 RSVPs.
Friday, June 20, 2014
Geekcitement
 |
| Pirates code in arrrrrrr (R). Source: http://constructingkids.com/2013/08/23/coding-pirates-beta-test-invitation/ |
I'm really excited to be attending DC2's workshop tomorrow, High-performance Computing in R. I'll post a recap here after the class.
I've gotten quite good at R coding over the last couple years. I've posted before that those who would complain about R's speed are likely not putting enough thought into their coding. R is a vectorized language. So, study your matrix algebra, people! (Also, note that R is an interpreted language; it can only go so fast even at its best.)
There are, however, some things that you can't vectorize. Gibbs sampling, for example, is index dependent. For example, your sample at iteration j + 1 is dependent on the result of your sample at iteration j. For this, C, C++, and Fortran play nicely with R.
There's also the issue of parallelization. I use the snowfall package regularly with great success. I am lately interested in playing with CUDA-enabled GPUs to get more cores. Not sure if this'll be covered in the course, but we'll see.
Friday, May 30, 2014
Friday links: May 30, 2014

Image via Simply Statistics
Explanation vs prediction as the goal of statistical models - H/T Majid alDosari,
Talking about uncertainty in science to lay audiences (possible repost)
Whole lotta slides about R and finance - H/T Revolutions
Big data is a social construct I
Big data is a social construct II - source of the image above. Note that (even using real, non whiteboard, data) we are on trend in terms of data size. We're above trend for data utilization.
What statistics teaches us about big data
Tuesday, May 27, 2014
Analogies from the past
BigData-Startups ponders on the rise of (or heretofore lack thereof) the Chief Data Officer / Chief Analytics Officer
They go on to quote Jeff Jonas of the Wall St. Journal:
What's happening? Why would organizations fail to adopt successful strategies that are--to we data geeks, at least--self-evidently the right thing to do to achieve the organization's objectives?
Erik Brynjolfsson and Andrew McAfee offer a compelling analogy from history. When factories were powered by steam, a single power plant was placed in the center of the factory. That power plant turned an axle. Factories were built up so that as many machines could be as close to that central axle as possible. Machines were placed based on their power needs, irrelevant to the factory's workflow.
When electric power began to replace steam power, factory owners simply replaced the central steam power plant with a central electric power plant. They saved a few pennies on energy costs and then went about their business.
It took years, a new generation of managers and factory owners, and budgets to build new factories to truly reap the rewards of electric power. New factories were built flat, every machine had its own small electric power plant. Machines were laid out according to the workflow of manufacturing a product. Huge efficiencies were gained in manufacturing. Profits went up while the price of manufactured goods went down. Society wins.
How does this apply today? We're still building our factories vertically. Those organizations and managers who have embraced a data-centric culture, it's not always obvious what the optimal data approach is. These things take time to work out, but the change is coming.
A data and analytics aware culture is in most businesses not present. Why not? Because revenue and profits are still flowing in at the end of the month and there is no sense of urgency or importance. There is basically no fire to do things differently.
They go on to quote Jeff Jonas of the Wall St. Journal:
The biggest obstacle preventing companies from taking full advantage of their data is likely outdated information-sharing policies.
What's happening? Why would organizations fail to adopt successful strategies that are--to we data geeks, at least--self-evidently the right thing to do to achieve the organization's objectives?
Erik Brynjolfsson and Andrew McAfee offer a compelling analogy from history. When factories were powered by steam, a single power plant was placed in the center of the factory. That power plant turned an axle. Factories were built up so that as many machines could be as close to that central axle as possible. Machines were placed based on their power needs, irrelevant to the factory's workflow.
When electric power began to replace steam power, factory owners simply replaced the central steam power plant with a central electric power plant. They saved a few pennies on energy costs and then went about their business.
It took years, a new generation of managers and factory owners, and budgets to build new factories to truly reap the rewards of electric power. New factories were built flat, every machine had its own small electric power plant. Machines were laid out according to the workflow of manufacturing a product. Huge efficiencies were gained in manufacturing. Profits went up while the price of manufactured goods went down. Society wins.
How does this apply today? We're still building our factories vertically. Those organizations and managers who have embraced a data-centric culture, it's not always obvious what the optimal data approach is. These things take time to work out, but the change is coming.
Friday, May 23, 2014
Friday links - May 23, 2014

An excellent overview of machine learning algorithms and techniques
More thoughts on statistics and data science (Personally, I think slides 35 on hit the nail on the head.) H/T Data Science Weekly
Source of the above: "The term big data is going to disappear in the next 2 years. Statistics will be what remains." I've pondered this myself, though I am not sure I agree. (I am not sure I disagree either.)
Despite the title, another case of human + computer > computer
Ensemble methods in R: part 1, part 2, part 3
Repeated for the end of the week: "5 Monday reads in Robotics, Artificial Intelligence, and Economics"
Thursday, May 22, 2014
Late Career Moves to Analytics
I recently read this article: Planning a late career shift to Analytics / Big data? Better be prepared!
Kunal Jain gives a sober perspective on the issue that hit close to home for me:
I came to this painful realization several years back. As a former Marine and non-commissioned officer, I had 3 "direct reports" before turning 21 and had significant formal leadership training and experience. I knew that much of that wouldn't count getting my first job out of college at 27, but that I could use those experiences to quickly rise in my career. Indeed, this is what several of my former military friends did. (One became a project manager 4 months after graduation, a feat that would normally have taken several years at best.)
This was my plan until I discovered economics--beautiful beautiful economics--at the end of my sophomore year. Suddenly, that past leadership experience counted for very little. Stata, SAS, and SQL did not care that I could turn objectives into plans and delegate. They cared only that my syntax was correct. My professors, and later employers, needed me to have solid foundations in calculus and probability. My public speaking skills would not matter if I couldn't produce analyses worth talking about. The learning curve was steep, especially since I failed algebra the first time, eked by with a D in geometry, and stopped taking high school math as soon as I could. Math is hard.
It took years of formal and self-guided education, coding, and real-world projects before my analytic capabilities were at a level where I could be trusted to design and lead analyses in the real world. It wasn't just a full-time job, it became a complete lifestyle. It has, however, paid off. Years of frustration and feeling as though I'd set myself back have given way to some of the most intellectually fulfilling work I've done. And at 32, I no longer feel as though becoming a Marine had "set back" my career. (Even if it had, I wouldn't have done anything differently.)
The learning curve can be steep. Those that would move into an analytics later in there career should consider their motivation for doing so.
As Kunal points out:
Kunal Jain gives a sober perspective on the issue that hit close to home for me:
Non technical experience will not count in your analytics jobs – the only benefit you might get is that the interviewer can expect you to be more mature with your thought process / decision.
I came to this painful realization several years back. As a former Marine and non-commissioned officer, I had 3 "direct reports" before turning 21 and had significant formal leadership training and experience. I knew that much of that wouldn't count getting my first job out of college at 27, but that I could use those experiences to quickly rise in my career. Indeed, this is what several of my former military friends did. (One became a project manager 4 months after graduation, a feat that would normally have taken several years at best.)
This was my plan until I discovered economics--beautiful beautiful economics--at the end of my sophomore year. Suddenly, that past leadership experience counted for very little. Stata, SAS, and SQL did not care that I could turn objectives into plans and delegate. They cared only that my syntax was correct. My professors, and later employers, needed me to have solid foundations in calculus and probability. My public speaking skills would not matter if I couldn't produce analyses worth talking about. The learning curve was steep, especially since I failed algebra the first time, eked by with a D in geometry, and stopped taking high school math as soon as I could. Math is hard.
It took years of formal and self-guided education, coding, and real-world projects before my analytic capabilities were at a level where I could be trusted to design and lead analyses in the real world. It wasn't just a full-time job, it became a complete lifestyle. It has, however, paid off. Years of frustration and feeling as though I'd set myself back have given way to some of the most intellectually fulfilling work I've done. And at 32, I no longer feel as though becoming a Marine had "set back" my career. (Even if it had, I wouldn't have done anything differently.)
The learning curve can be steep. Those that would move into an analytics later in there career should consider their motivation for doing so.
As Kunal points out:
Take this up only if you tick all the boxes below:
- You are absolutely crazy about this industry. You can’t help but analyze any numbers you come across – I play with numbers on the number plate of any vehicle which passes me.
- You have undergone a few courses on Coursera / eDX and have excelled at them. You have submitted all the assignments and have scored extremely well.
- You have the perseverance and motivation to undergo 2 – 3 years of arduous work learning about a new knowledge intensive domain.
- You are willing to spend a lot of time as Individual Contributor
Tuesday, May 20, 2014
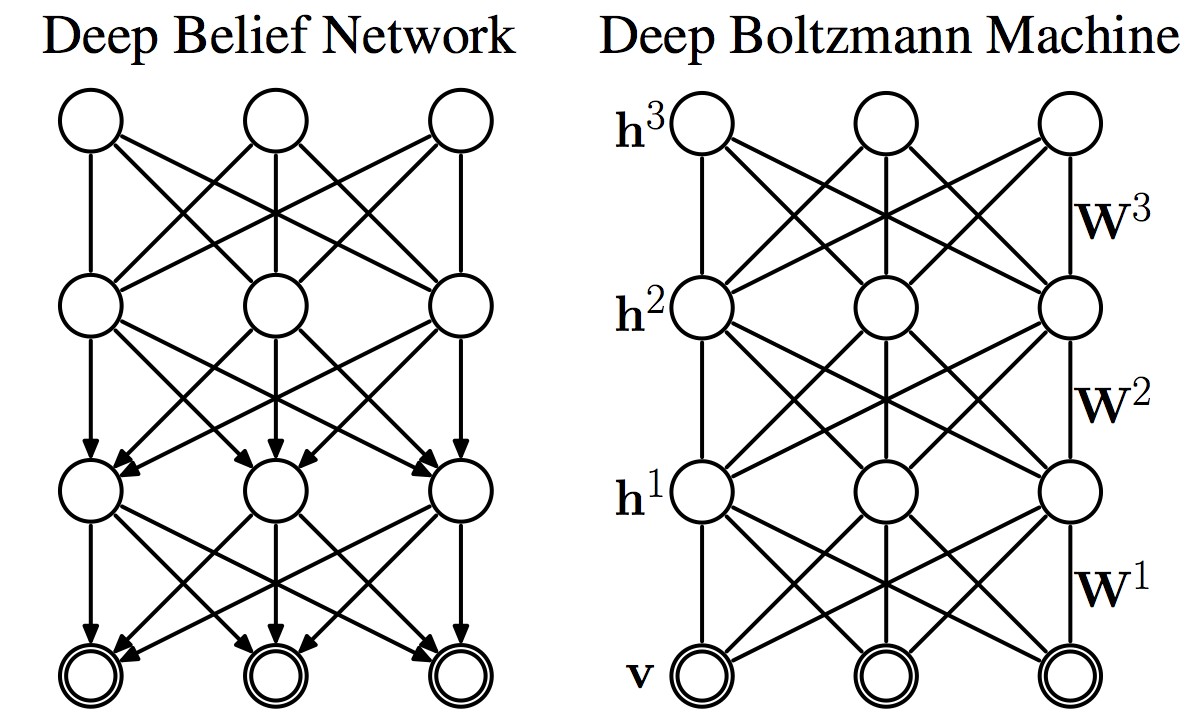
More on deep learning
Friday, May 16, 2014
Friday Links: May 16, 2014
Thursday, May 15, 2014
Follow up: Make the R go!
I posted this link to Hadley Wickham's e-book, Advanced R Programming, earlier.
Turns out the Data Community DC is hosting a workshop on that very topic.
For context: I have learned theses things in the last year or so:
Turns out the Data Community DC is hosting a workshop on that very topic.
For context: I have learned theses things in the last year or so:
- Many operations are embarrassingly parallel.
- Some operations have to be performed in sequence; R does not do so well here. Proceed with your "for loop" with caution. (Though sometimes it's just fine, situation dictates.)
- The best way to address (2) is with some good old fashioned C, C++, or Fortran. ("I was coding in Fortran before it was cool." *Throws down latte, puts on Ray Bans, takes Macbook out of cafe*)
Tuesday, May 13, 2014

{kind=link}
{kind=link}
Thursday, May 8, 2014
Jeff Leek asks questions near and dear to my heart
In the latest post on Simply Statistics, Jeff Leek asks some good questions:
One area that I see as being quite underdeveloped in data science is how it approaches time series data. For that, we should look to the econometricians as much as statisticians. (What's the difference between an econometrician and a statistician? About $15 K a year. Boom.) I am a fan of David Hendry's approach and I think the data science community would like it as well. He calls it "general to specific" modeling and I've seen a similar approach used to build machine-learning models.
Oh, but I'm off topic...
Anyway, the title of Leek's post "Why big data is in trouble: they forgot about applied statistics" is a bit melodramatic. Big data isn't in trouble because big data isn't going anywhere. (By big data, I mean the concept of a data-driven world.) As I said in an earlier post,
I look forward to the day that "data science" applications become mainstream in the statistics community. Then we'll really be cookin' with Crisco!
I'd say that (1) is changing, if slowly. But (2) is a good message for non-statistical folks in the data science community. Statistics is a field that is both wide and deep. There are many pressing data science problems that have been addressed in some fashion by someone in the statistics community. In many cases, we don't need to reinvent the wheel.
- Given the importance of statistical thinking why aren't statisticians involved in these initiatives?
- When thinking about the big data era, what are some statistical ideas we've already figured out?
One area that I see as being quite underdeveloped in data science is how it approaches time series data. For that, we should look to the econometricians as much as statisticians. (What's the difference between an econometrician and a statistician? About $15 K a year. Boom.) I am a fan of David Hendry's approach and I think the data science community would like it as well. He calls it "general to specific" modeling and I've seen a similar approach used to build machine-learning models.
Oh, but I'm off topic...
Anyway, the title of Leek's post "Why big data is in trouble: they forgot about applied statistics" is a bit melodramatic. Big data isn't in trouble because big data isn't going anywhere. (By big data, I mean the concept of a data-driven world.) As I said in an earlier post,
It may be tempting to see [Google Flu] as justification that big data/data science is just media buzz. However, the technology that makes acquiring these data easy is here to stay. Reconciling statistical best-practices and big data is actively being discussed in the data science and big data communities.
I look forward to the day that "data science" applications become mainstream in the statistics community. Then we'll really be cookin' with Crisco!
Tuesday, May 6, 2014
Friday Links (from last Friday): May 2, 2014
I was traveling last Friday and just realized I hadn't set this up to automatically post while I was away. Whoops.
Big Data... Big Deal?
Forbes has a history of data science. (This is fantastic, by the way.)
Deep dive: R vs SAS - I was a respondent to this survey and was quoted in the flash release. “R. But isn’t the debate more between R and Python?”
Write your own R package - I plan to do just that. Currently I "source()" a handful of files full of functions that I use daily.
While we're on the topic, read Advanced R Development
Big Data... Big Deal?
Forbes has a history of data science. (This is fantastic, by the way.)
Deep dive: R vs SAS - I was a respondent to this survey and was quoted in the flash release. “R. But isn’t the debate more between R and Python?”
Write your own R package - I plan to do just that. Currently I "source()" a handful of files full of functions that I use daily.
While we're on the topic, read Advanced R Development
Friday, April 25, 2014
Thursday, April 24, 2014
From 1998 (!): Statistics should be rebranded as "data science."
Identity of statistics in science examinedC. F. Jeff Wu, professor of statistics, will present “Statistics = Data Science” at 4:10 p.m. Nov. 10 in Rackham Amphitheater. The lecture, in honor of Wu’s appointment to the H. C. Carver Collegiate Professorship in Statistics, will focus on the identity of statistics in science. Contrary to the perception of statistics as tables and figures, Wu characterizes statistical work as data modeling, analysis and decision making. He will conclude his lecture by proposing that statistics be renamed “data science” and statisticians “data scientists.”
I'm still processing this... 1998! That was 16 years ago. More on Jeff Wu is on Wikipedia.
Tuesday, April 22, 2014
It's all about the Beta
I am presenting a paper at this year's Joint Statistical Meetings (JSM). (It is also my first JSM.) The abstract is below.
What does it mean? You'll have to come see me talk to find out. ;)
If you'll be there, it's session 617 on the last day of the conference, August 7. They've got me slated for 8:30 AM; don't drink too much the night before.
Johnathan Chang's lda package for R. (It converges much faster than topicmodels. I am personally not a fan of topic modeling with MALLET in R or Java.)
Wikipedia uses LDA as an example of a Dirichlet Multinomial distribution. (For the record, and with no offense to David Blei or any of the other brilliant folks doing topic modeling research, this Wikipedia example is much easier to understand than any "official" explanation I've read in a research paper so far.)
The BEST short paper on Gibbs sampling to fit/learn an LDA model.
What makes LDA better than pLSA? Why is Gibbs sampling different from variational Bayes? It's all about the priors, stupid.
Goldwater, Griffiths, and Johnson almost scooped me (in 2011). While they aren't as explicit about the LDA Zipf's law link as I am (will be?), they have a general framework for linguistic models of which LDA is a specific case.
Hey, are you modeling language? You should be reading Thomas Griffiths. At the very least, read this article. Ok ok. Only if you're actually interested in understanding causality in language models, you should read Griffiths.
Latent Dirichlet Allocation (LDA) is a popular hierarchical Bayesian model used in text mining. LDA models corpora as mixtures of categorical variables with Dirichlet priors. LDA is a useful model, but it is difficult to evaluate its effectiveness; the process that LDA models is not how people generate real language. Monte Carlo simulation is one approach to generating data where the "right" answers are known a priori. But sampling from the Dirichlet distributions that are often used as priors in LDA do not generate corpora with the property of natural language known as Zipf's law. We explore the relationship between the the Dirichlet distribution and Zipf's law within the framework of LDA. Considering Zipf's law allows researchers to more-easily explore the properties of LDA and make more-informed a priori decisions when modeling real textual data.I will cut to the chase: If you generate data with a process mimicking LDA, the term frequency of the generated corpus depends only on beta, the Dirichlet parameter for topics distributed over words. Alpha factors out and sums to one.
What does it mean? You'll have to come see me talk to find out. ;)
If you'll be there, it's session 617 on the last day of the conference, August 7. They've got me slated for 8:30 AM; don't drink too much the night before.
Some LDA resources I've found helpful:
Johnathan Chang's lda package for R. (It converges much faster than topicmodels. I am personally not a fan of topic modeling with MALLET in R or Java.)
Wikipedia uses LDA as an example of a Dirichlet Multinomial distribution. (For the record, and with no offense to David Blei or any of the other brilliant folks doing topic modeling research, this Wikipedia example is much easier to understand than any "official" explanation I've read in a research paper so far.)
The BEST short paper on Gibbs sampling to fit/learn an LDA model.
What makes LDA better than pLSA? Why is Gibbs sampling different from variational Bayes? It's all about the priors, stupid.
Goldwater, Griffiths, and Johnson almost scooped me (in 2011). While they aren't as explicit about the LDA Zipf's law link as I am (will be?), they have a general framework for linguistic models of which LDA is a specific case.
Hey, are you modeling language? You should be reading Thomas Griffiths. At the very least, read this article. Ok ok. Only if you're actually interested in understanding causality in language models, you should read Griffiths.
Friday, April 18, 2014
Friday links April 18, 2014
This is the "where did you go?" edition of Friday links. This is a pretty lame excuse: I've been organizing my files. Specifically, I have data on three laptops, a desk top, an external hard drive, 4 thumb drives, 3 cell phones..... You get the idea. I've been separating the wheat from the chaff, storing it, and then wiping the disk. It's more time-consuming than I'd thought.
Nevertheless, you care about links and not my excuses!
More on how R works, AKA how to not fail at coding in R.
Someone just brought r/dataisbeautiful to my attention.
SAS vs R
"Instead of programming people to act like robots, why not teach them to become programmers, creative thinkers, architects, and engineers?"
Nevertheless, you care about links and not my excuses!
More on how R works, AKA how to not fail at coding in R.
Someone just brought r/dataisbeautiful to my attention.
SAS vs R
"Instead of programming people to act like robots, why not teach them to become programmers, creative thinkers, architects, and engineers?"
Friday, April 11, 2014
Friday Links April 11, 2014
"The History of statistics can be said to start around 1749 although, over time, there have been changes to the interpretation of the word statistics." - From Wikipedia and an interesting read
Nine problems with big data.
As a statistician, I often believe it is my job to be the wet blanket in the room. Data scientists, welcome to the club.
R is bringing open source to science. And is R slow, or are you writing slow code? (You're probably writing slow code.)
What drives the research of self-driving cars?
Nine problems with big data.
As a statistician, I often believe it is my job to be the wet blanket in the room. Data scientists, welcome to the club.
R is bringing open source to science. And is R slow, or are you writing slow code? (You're probably writing slow code.)
What drives the research of self-driving cars?
Wednesday, April 2, 2014
Google Flu + Data Science and Statisticians (again)
Several people have emailed me with articles on the fallout from Google Flu’s big flop in the past week. A Financial Times article in particular stood out to me as being an excellent statement on the state of data science vis-a-vis statistical rigor.
A common criticism of big data/data science is that exuberance has caused folks to erroneously believe they can ignore basic statistical principles if they have “big data” and that statistics is only for “small data.” This seems to be what happened to Google Flu and the Financial Times makes that same case.
Big data and data science have most certainly been over hyped recently. It may be tempting to see this as justification that big data/data science is just media buzz. However, the technology that makes acquiring these data easy is here to stay.
Reconciling statistical best-practices and big data is actively being discussed in the data science and big data communities. (I can point to this post at Data Community DC as one piece of evidence.) There are also several university statistics programs that are actively bringing statistical rigor to big data/data science issues. (Stanford and Berkeley come immediately to mind.)
My tactic when discussing these issues in a professional settings has been to be a voice of caution if the audience is excited and to be the voice of optimism if the audience is skeptical. Google Flu is a perfect example of the promise and peril associated with big data and data science; the timing and volume of the data can add to predictive power, but poor design can lead to models that confidently point to the wrong answer. (We statisticians call this “bias”.)
A common criticism of big data/data science is that exuberance has caused folks to erroneously believe they can ignore basic statistical principles if they have “big data” and that statistics is only for “small data.” This seems to be what happened to Google Flu and the Financial Times makes that same case.
Big data and data science have most certainly been over hyped recently. It may be tempting to see this as justification that big data/data science is just media buzz. However, the technology that makes acquiring these data easy is here to stay.
Reconciling statistical best-practices and big data is actively being discussed in the data science and big data communities. (I can point to this post at Data Community DC as one piece of evidence.) There are also several university statistics programs that are actively bringing statistical rigor to big data/data science issues. (Stanford and Berkeley come immediately to mind.)
My tactic when discussing these issues in a professional settings has been to be a voice of caution if the audience is excited and to be the voice of optimism if the audience is skeptical. Google Flu is a perfect example of the promise and peril associated with big data and data science; the timing and volume of the data can add to predictive power, but poor design can lead to models that confidently point to the wrong answer. (We statisticians call this “bias”.)
Monday, March 31, 2014
The cost of studying Data Science
Simply Statistics has a ("non-comprehensive") breakdown of costs associated with various data science educational programs. The list includes MOOCs and traditional degree programs at the Masters and Doctoral levels. Check it out.

Full disclosure: The guys at Simply Statistics are teaching the JHU data science certificate course. There are many other programs that are ostensibly data science programs as well, whether they call themselves "data science" or otherwise. (They did say it was non-comprehensive, after all.)

Full disclosure: The guys at Simply Statistics are teaching the JHU data science certificate course. There are many other programs that are ostensibly data science programs as well, whether they call themselves "data science" or otherwise. (They did say it was non-comprehensive, after all.)
Friday, March 28, 2014
Friday Links Mar 28, 2014
Set up your own VPN
Deep learning and NLP - This is a follow on (for me) from Monday's DC2 deep learning lecture (which was excellent)
Clusters may be less separated in real life than in the classroom. - You don't say?
The Sunlight Foundation's If This Then That channel
A timeline of statistics
Jeff Leek's take on what my stat professors called the "principal of parsimony"
Krugman on Paul Pfleiderer on assumptions in modeling - This was written for economics, but in principle it's relevant to anyone doing quantitative modeling.
Inside the algorithms predicting the future!
A bit on Bayesian statistics
Some links on Thomas Piketty - (1, 2, 3) HT to Marginal Revolution for some of these. I have Piketty's book and am looking forward to reading it when things slow down. (Read: when I stop taking work home with me.)
Deep learning and NLP - This is a follow on (for me) from Monday's DC2 deep learning lecture (which was excellent)
Clusters may be less separated in real life than in the classroom. - You don't say?
The Sunlight Foundation's If This Then That channel
A timeline of statistics
Jeff Leek's take on what my stat professors called the "principal of parsimony"
Krugman on Paul Pfleiderer on assumptions in modeling - This was written for economics, but in principle it's relevant to anyone doing quantitative modeling.
Inside the algorithms predicting the future!
A bit on Bayesian statistics
Some links on Thomas Piketty - (1, 2, 3) HT to Marginal Revolution for some of these. I have Piketty's book and am looking forward to reading it when things slow down. (Read: when I stop taking work home with me.)
Wednesday, March 26, 2014
Tyler Cowen on the Alleged Wage Suppression Scheme in Silicon Valley
There's been some consternation and indignation lately pointed towards Silicon Valley execs who may have conspired not to recruit from each others' firms.
Tyler Cowen weighs in:
To me, it seems the way to think about this situation breaks down to two questions:
Tyler Cowen weighs in:
"I would suggest caution in interpreting this event. For one thing, we don’t know how effective this monopsonistic cartel turned out to be. [...] It is hard to find examples of persistently successful monopsonistic labor-buying cartels."
To me, it seems the way to think about this situation breaks down to two questions:
- Was the law broken, irrespective of the economics of the situation?
- Factoring in economics, should this be illegal?
The answers to 1 and 2 (and how they interact with each other) ought to drive one's thinking on the issue.
Update 5/23/2014 - looks like they settled.
Update 5/23/2014 - looks like they settled.
Tuesday, March 25, 2014
Toys
I'm looking into upgrading my personal computing situation. I get to play with some fancy tech at work, but at home, I'm running Windows XP on a laptop that was mediocre when it was new... in 2008. My desktop was mediocre in 2006.
For surfing the web and watching Netflix, a tablet and my ghetto desktop hooked up to the TV are fine. But I occasionally do my own research outside of work. I've also got personal data on a handful of thumb drives, and external hard drive, and the last 3 laptops I've owned. I keep the latter in a box under the printer just in case I need something on them. This needs to change.
I am a fan of Linux, though I can't claim to be an expert. A colleague suggested making the change to Apple with a Macbook air for that very reason. I was considering it for a while, but I just don't see the value for money. For $1,550 I can get 8 G of RAM, 256 G of flash storage, and a dual core processor running at 1.7 GHz. Not really something to write home about considering the price. (For the record, I don't really care about graphics etc. I need to crunch data.)
I recently stumbled across System76, a maker of computers designed to use Linux (Ubuntu, specifically) as the primary OS. For $1,333 I can get 16 G of RAM, 240 G of flash storage, and a quad core processor with hyperthreading (that's an additional 4 virtual cores) pumping 2.0 GHz. I save $200 and get more power and memory? Ooh, baby. Sign me up.
I can spend that $200 on a 4 TB data store, though that would be a mechanical HD rather than flash storage.
I learned last night at DC2's event, A Short History of and Introduction to Deep Learning, that I can get a couple GTX 580 GPUs up and running for less than $600. Hamina hamina. It'll take me longer to teach myself deep learning than it'll take to buy the hardware to use it.
For surfing the web and watching Netflix, a tablet and my ghetto desktop hooked up to the TV are fine. But I occasionally do my own research outside of work. I've also got personal data on a handful of thumb drives, and external hard drive, and the last 3 laptops I've owned. I keep the latter in a box under the printer just in case I need something on them. This needs to change.
I am a fan of Linux, though I can't claim to be an expert. A colleague suggested making the change to Apple with a Macbook air for that very reason. I was considering it for a while, but I just don't see the value for money. For $1,550 I can get 8 G of RAM, 256 G of flash storage, and a dual core processor running at 1.7 GHz. Not really something to write home about considering the price. (For the record, I don't really care about graphics etc. I need to crunch data.)
I recently stumbled across System76, a maker of computers designed to use Linux (Ubuntu, specifically) as the primary OS. For $1,333 I can get 16 G of RAM, 240 G of flash storage, and a quad core processor with hyperthreading (that's an additional 4 virtual cores) pumping 2.0 GHz. I save $200 and get more power and memory? Ooh, baby. Sign me up.
I can spend that $200 on a 4 TB data store, though that would be a mechanical HD rather than flash storage.
I learned last night at DC2's event, A Short History of and Introduction to Deep Learning, that I can get a couple GTX 580 GPUs up and running for less than $600. Hamina hamina. It'll take me longer to teach myself deep learning than it'll take to buy the hardware to use it.
Friday, March 21, 2014
Friday Links Mar 21, 2014
IBM's Watson is looking into genetics and cancer
Get the right data scientists to ask the "wrong" questions - I've used similar methods myself to great success.
"Sloppy researchers beware. A new institute has you in its sights"
So you want to be a data scientist...
Talking about uncertainty in the scientific process
A Bayesian reading list
Economics and the foundations of artificial intelligence
Get the right data scientists to ask the "wrong" questions - I've used similar methods myself to great success.
"Sloppy researchers beware. A new institute has you in its sights"
So you want to be a data scientist...
Talking about uncertainty in the scientific process
A Bayesian reading list
Economics and the foundations of artificial intelligence
Intelligence as skill vs innate quality (only loosely statistically-related)
Sparse updates the last couple of weeks. I've been busy at work and enjoying the (slow) return of spring here in the DC area in my time off. Hasn't left much time for blogging.
As I said in my last post, I've been reading The Second Machine Age. Stories about IBM's Watson and other learning machines got me thinking about how we view intelligence as a society. These days, I think, we tend to view intelligence as an innate quality, albeit one that's shaped by education.
I read an article (that I desperately tried to find so I could link to it here, sorry) stating that in ancient Greece, intelligence was viewed as a skill. One could look at the habits and practices of an intelligent person and emulate them to boost one's own intelligence.
Flash forward: I've met some really smart people over the years. They might wax poetic about intelligence in the abstract. However, if one was to ask them something concrete like, "how should I study for the upcoming midterm?" You'd get a pretty concrete answer about organizing information, tips and tricks for memorizing theorems, what to do the day of the test, etc. They'd be unlikely to say, "if you're smart, you'll do well."
I'd also add that when I was in the Marines, they had a similar view of preparation for battle. We called it the 7 P's. Prior Planning and Preparation Prevent Piss Poor Performance. Not much in there about being born a certain way.
The debate over intelligence being innate versus a skill rages on. I wonder what our journey to create "smart" machines will ultimately tell us about ourselves?
(For the record: when the singularity looks like it's getting close, I'm going to start carrying around a pocket full of magnets just in case...)
Subscribe to:
Posts (Atom)